研究分野
持橋研究室では, 自然言語処理および離散データの機械学習を中心に, 以下のように幅広い分野にまたがって研究および共同研究を行っています. 下では, その一部を紹介しています.
統計的自然言語処理教育工学・心理統計学
ロボティクスと自然言語処理
政治学方法論と自然言語処理
音楽・音声情報処理と自然言語処理
脳計測による情動情報と自然言語処理
科学計量学
統計的自然言語処理
ホログラフ埋め込みに基づくCCG構文解析
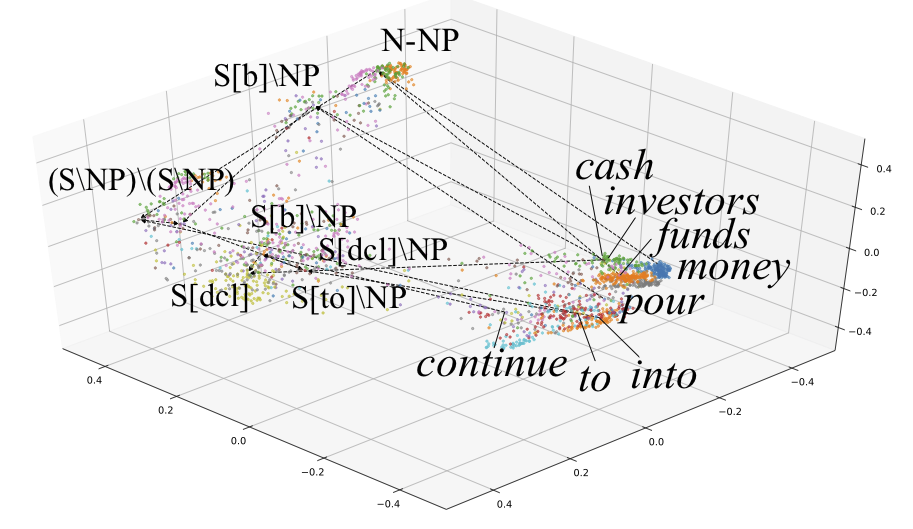
ホログラフ埋め込み(Plate 1995)は, 2つの埋め込みベクトルの「重ね合わせ」を計算する方法で, 知識グラフの表現にも使われています(Nickel+ 2016). 我々は, これをCCG(組み合わせ範疇文法)における単語および句構造の埋め込みベクトルの合成に用いることで, Socher(2013)のCVGのように合成に余分なパラメータを必要とせず, 埋め込み空間において木構造を数学的に見通しよく表現できるホログラフCCG構文解析を提案しました. 提案法は, C&Cパーザを用いる中で世界最高精度を達成し, 独自の構文解析器の性能は, Transformerを併用したブラックボックスの深層学習とほぼ同等となっています.
(立命館大 谷口研 山木さんとの共同研究)
[発表文献: ACL 2023(オーラル)] [発表文献: NLP2022 (若手奨励賞)]
無限木構造隠れMarkovモデル (iTHMM)
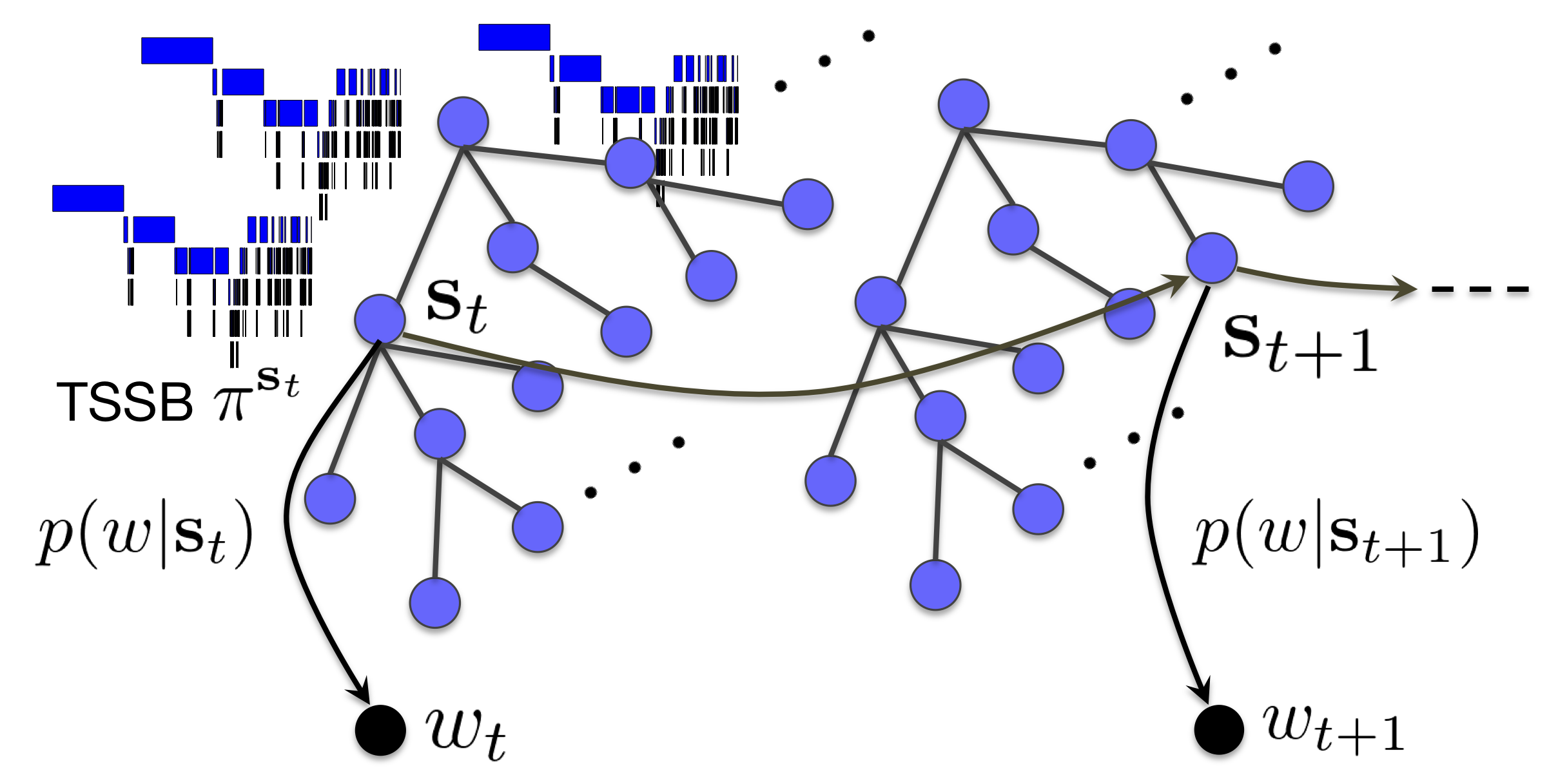
名詞や動詞, 形容詞といった品詞は, 隠れマルコフモデル(HMM)をベイズ学習することで, かなり高精度に教師なし学習できることが知られており(Goldwater+ 2007), 品詞の数もノンパラメトリックベイズ法で推定することができます(van Gael+ 2008).
しかし, 実際の品詞は「名詞─一般名詞─人名」のように階層化されており, これを教師なし学習するのは, 無限個の分岐の下に無限個の分岐が続き, ほとんど不可能なように見えます. この問題に対し, 木構造棒折り過程(TSSB, Adams+ 2010)をさらに階層化した階層的TSSBを用い, 巧妙なギブスサンプリングによって学習を可能にしたのが無限木構造HMM (iTHMM)です. iTHMMでは, 観測された単語列だけから, 背後に隠れた品詞の木構造とその分岐の数をノンパラメトリックベイズ法によって学習し, 階層的な品詞を教師なし学習することができます. 本研究は, 2017年度の情報処理学会山下記念研究賞を受賞しています.
[発表文献: NL226 (情報処理学会山下記念研究賞)]
教師なし形態素解析, 半教師あり形態素解析

日本語や中国語のような続け書きを行う言語において, 単語分割は重要な問題です. 最近は深層学習ではbyte-pairエンコーディングが使われますが, 「単語」とは何か, という問題は依然として計算言語学として興味深い問題です. 従来は単語分割は, 人手で単語境界を付与した教師あり学習によって行われてきましたが, この研究では階層Pitman-Yor過程に基づく文字-単語の階層nグラムモデルを仮定し, 完全なベイズ学習を行うことで, 文字列から「単語」を教師なし学習するベイズnグラム言語モデルを提案しました (ACL 2009). ここでは, 観測文字列の確率を最大にする単位として, 「単語」をMCMCで次々とサンプリングします.
さらに, 隠れた品詞も同時に教師なし学習する拡張も行い (ACL 2015), 人手で付与した教師データと大量の教師なしデータを融合する半教師あり学習も提案しています (TACL 2017).
(後者2つはデンソーITラボラトリおよび博報堂との共同研究)
[発表文献: NL190] [発表文献: ACL 2009] [発表文献: ACL 2015] [発表文献: TACL 2017]
∞グラム言語モデル
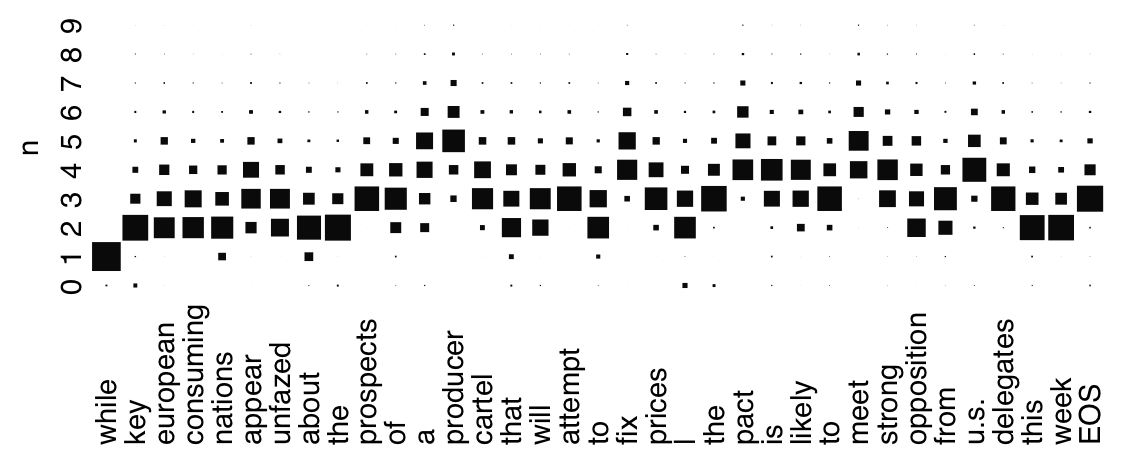
自然言語処理や音声認識で長く用いられてきたnグラムモデル(言語モデル)は, 何単語前までに依存するかというnを事前に指定する必要がありましたが, この研究ではnを文脈に依存する可変長の潜在変数とし, ノンパラメトリックベイズ法による言語モデルと組み合わせることで, nの指定を不要にし, 理論的に∞まで使用可能な「∞グラム言語モデル」を提案しました. これは, 統計的には完全可変オーダーのマルコフ過程ととらえることができます.
[発表文献: NL178] [発表文献: NIPS 2007(オーラル)]
文脈の動的ベイズ推定
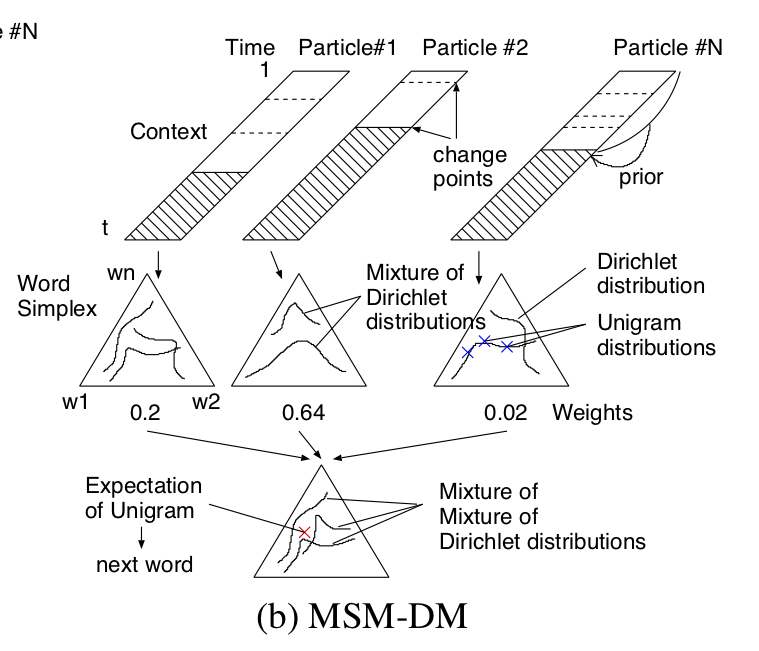
| 
|
[発表文献: NL165] [発表文献: NIPS 2005]
副詞の意味の数理モデル
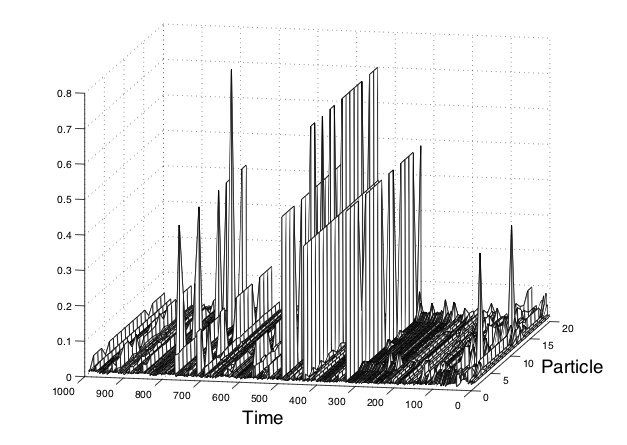
「丁寧に」「ゆっくり」「ヨボヨボ」など, 副詞の表す意味は, 今後ロボティクスがより人間に優しいインターフェースを実現するために重要だと考えられます. 副詞は動作の特徴を表していますが, 関数がどこを通るか(位相)ではなく, その関数の特徴が重要です. そこで我々の研究では, 副詞の意味を動作系列を表現するガウス過程のカーネルにおける周波数基底の混合モデルとみなし, スペクトル混合カーネル [Wilson+2013] とLDAを組み合わせることで, 動作とそれを表す副詞の意味を, 周波数空間での結合トピックモデルとして表現する方法を提案しました.
(お茶の水女子大 谷口さんとの共同研究)
[発表文献: NLP2021] [発表文献: PRMU2021]
ロボットの動作の「形態素解析」
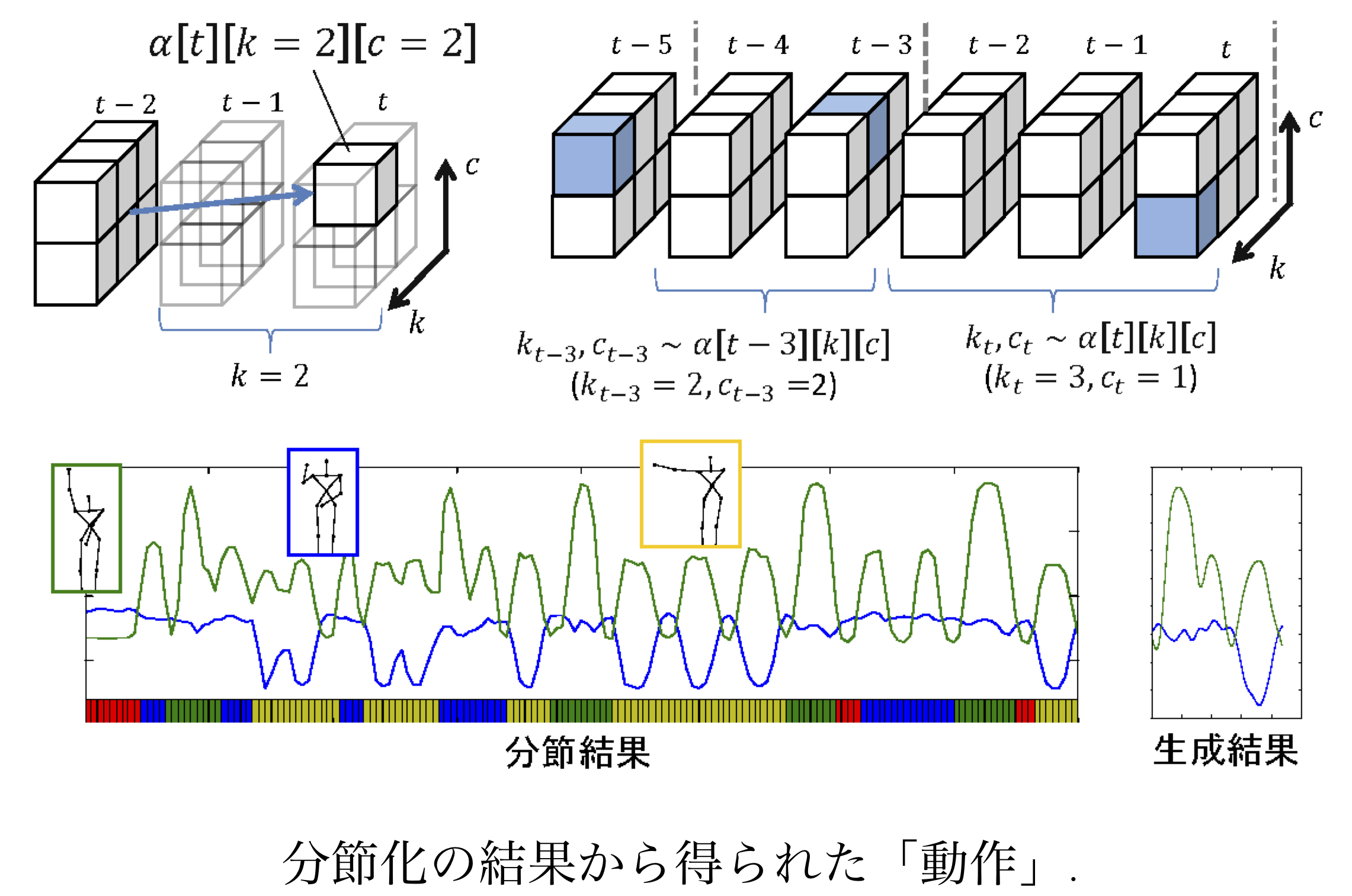
上の教師なし形態素解析を応用して, 各「単語」で文字列ではなく, ガウス過程による軌道を生成することで, ロボティクスにおいて関節角の時系列ベクトルから「動作」を「単語」として統計的に自動学習する研究を行っています. これは隠れセミマルコフモデルであるため各動作は潜在状態を持ち, その総数も階層ディリクレ過程によって自動的に学習されます. さらに, 高次元の観測データについてはVAEを用いることで, 圧縮された潜在空間でのガウス過程で分節化を行う方法も開発しています. この一連の研究は, ロボティクスのトップ国際会議IROSにおいて本会議論文として発表されています.
(電通大 長野さん他との共同研究)
[発表文献: IROS 2018] [発表文献: IROS 2019] [発表文献: Frontiers in Robotics and AI 2019] [発表文献: Frontiers in Robotics and AI 2022]
確率的潜在意味スケーリング (PLSS)

テキストを, 右翼-左翼, 外向的-内向的といったある軸で連続的に測定することは, 政治学や心理学, 文学などで重要な応用をもちます. このために, 単語ベクトルの空間において指定した軸上でテキストの項目反応理論を考え, 潜在的な連続値θを推定することのできる統計モデル, PLSS (確率的潜在意味スケーリング)を開発しました. PLSSはLSS (潜在意味スケーリング; Watanabe 2020)の統計的な拡張とみなすことができます. また, 正例/負例として与えたテキスト集合から, それを区別する潜在的な軸を最適化して求めることもできます. 政治学方法論における公開データ, および国会議事録においてその有効性を検証しています.
[発表文献: NL249 (NL研優秀研究賞受賞)]
音楽の「典型性」のモデル化

厖大な音楽が蓄積されている現在, 「典型的な歌」と「非典型的な歌」を区別することは重要です. ただし, 単に確率が高い歌を典型的とすると, 同じ音の連続する平板な歌が典型的ということになってしまいます. これに対して, 情報理論の「典型集合」の考え方を応用することで, 情報理論的に音楽の典型性を判断できる指標を提案しました. 論文は音楽情報処理のトップ国際会議ISMIR 2016に採録されています. 他に, 声のF0軌跡をガウス過程でモデル化する研究なども行っています.
(産総研 後藤グループ, NTT CS研との共同研究)
[発表文献: ISMIR 2016] [発表文献: ICASSP 2014] [発表文献: INTERSPEECH 2010]
局所的変分法による時系列非補償型IRT
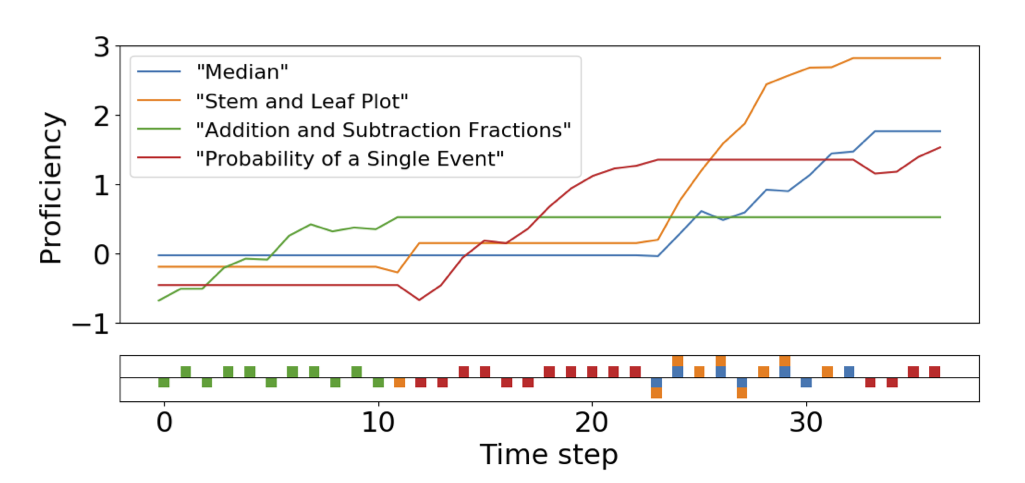 潜在スキルが問題を解くにつれて上昇する時系列の多次元項目反応理論(IRT)において,
必要な全てのスキルがないと問題に正解できない非補償型の設定で,
問題への正解/不正解の学習ログから,
複数の潜在スキルの向上をカルマンフィルタと変分法を用いて時系列的に推定する方法を示しました.
潜在スキルが問題を解くにつれて上昇する時系列の多次元項目反応理論(IRT)において,
必要な全てのスキルがないと問題に正解できない非補償型の設定で,
問題への正解/不正解の学習ログから,
複数の潜在スキルの向上をカルマンフィルタと変分法を用いて時系列的に推定する方法を示しました. (統計科学専攻 玉野さんとの共同研究)
[発表文献: Psychometrika 2023] [発表文献: IBISML研究会]
脳計測による情動情報と自然言語処理
科学研究費・学術変革領域(B)「情動情報解読による人文系学問の再構築」に採択され,
fMRIによる脳測定を中心とした研究も行っています.
詳しくは,
プロジェクトの公式サイトをご覧ください.